Part 1 covered the math. Part 2 built the architecture in PyTorch. Now we train the model on a long-range dependency task and look at what the gates actually learn.
Training Setup
We trained a 2-layer LSTM (128 hidden units, 204,290 parameters) on a synthetic task: classify a length-30 sequence based solely on its first and last elements. The 28 intermediate values are random noise. A standard RNN cannot solve this -- by the time it reaches the end of the sequence, the first element has been washed out by vanishing gradients.
Training details: Adam with lr $10^{-3}$, step scheduler halving every 20 epochs, gradient clipping at $\|\nabla\| = 1.0$, 100 epochs, 5,000 training sequences.
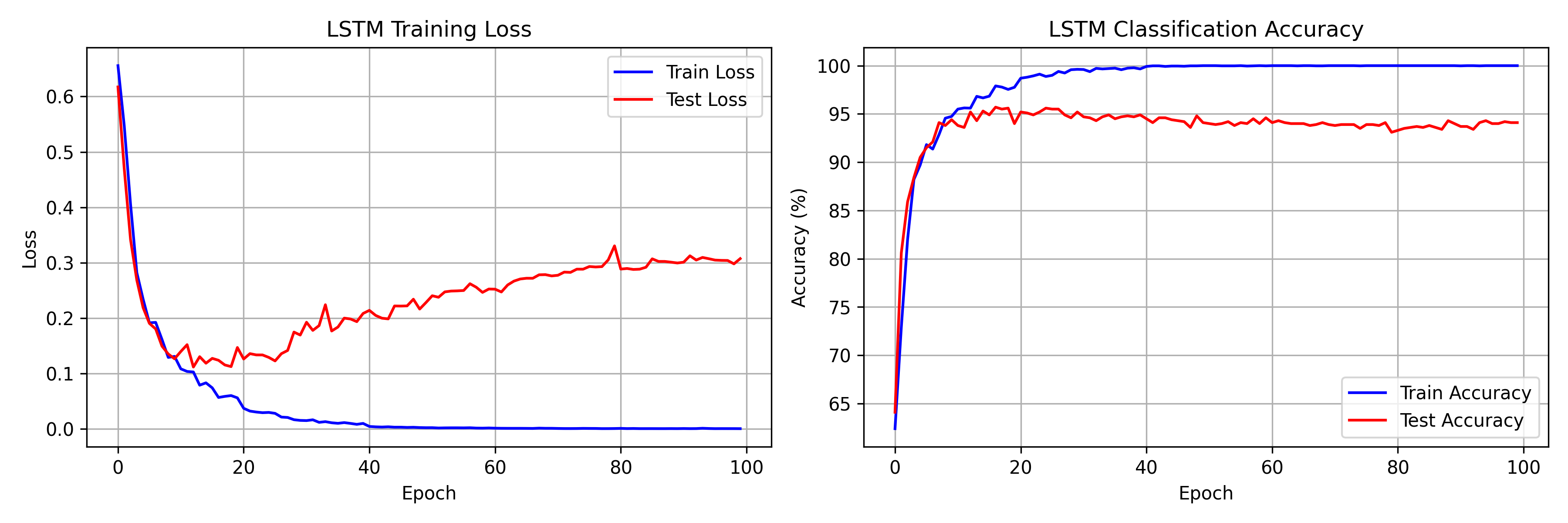
Training Results
From the training log:
- Epoch 1: 62.4% train / 64.1% test accuracy
- Epoch 8: first time above 94% test accuracy (94.1%)
- Epoch 17: peak test accuracy of 95.7%
- Epoch 50: 100% train accuracy, train loss 0.0020
- Epoch 100: train loss 0.0003, test accuracy 94.1%
The model cracks the task fast -- 90.5% test accuracy by epoch 5. The gap between the peak (95.7% at epoch 17) and the final test accuracy (94.1% at epoch 100) reflects overfitting on a small dataset, not a failure of the architecture.
Visualizing Gate Dynamics
To see how the LSTM solves this task, we extracted gate activations across all 30 time steps for 8 hidden units in the first layer.
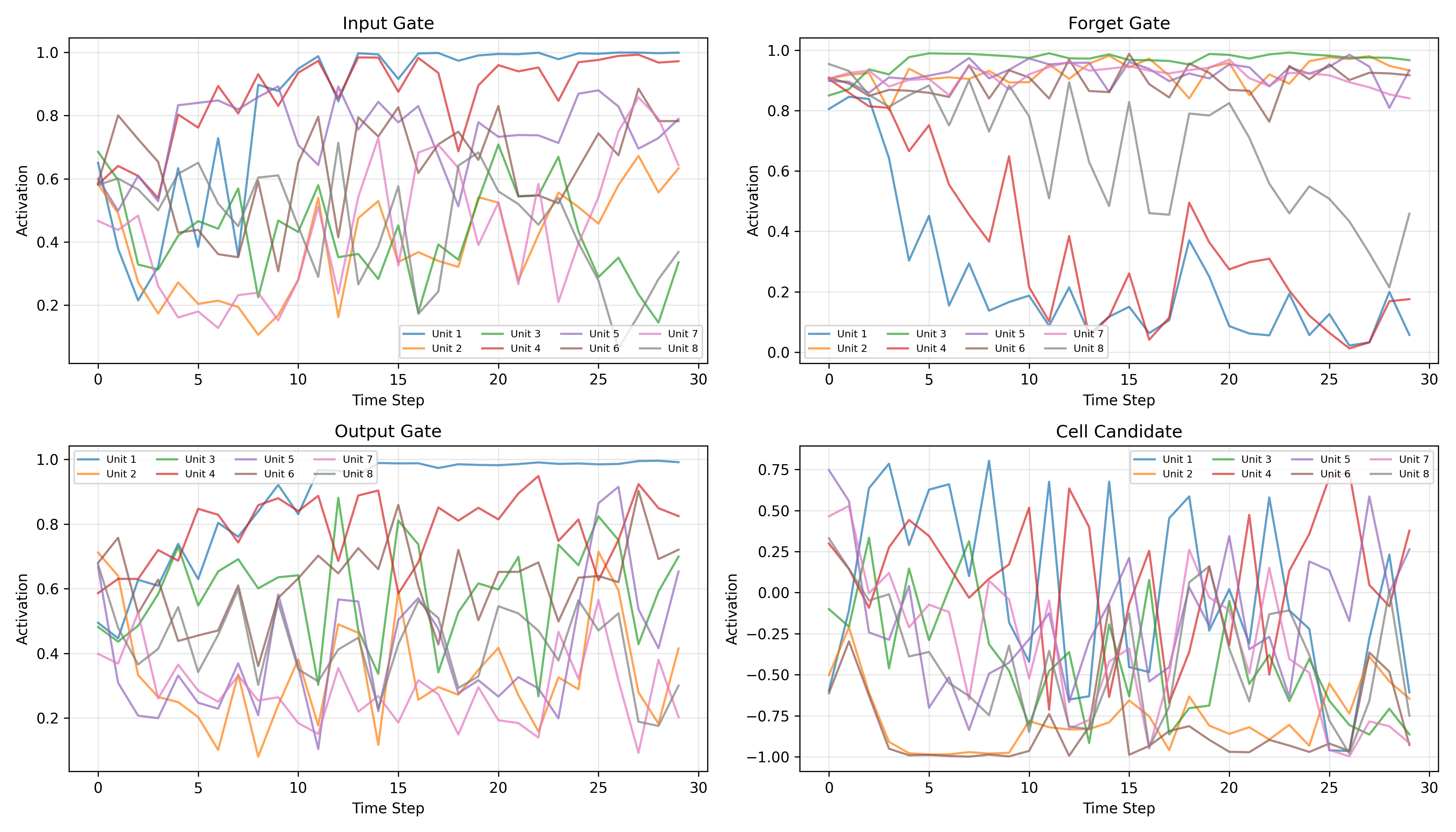
Forget Gate Patterns
Nearly all 8 units hold forget gate activations between 0.8 and 1.0 across the full sequence. This is the Constant Error Carousel in action -- the network learns to keep the gradient highway open so that error signals from the classification head can reach the first time step.
- High activation ($f_t \approx 0.8$-$1.0$): the dominant pattern, preserving cell state content
- Occasional dips: a few units briefly drop their forget gate, clearing specific memory slots
Input Gate Behavior
More varied than the forget gate:
- Some units (e.g., Unit 1, Unit 4) ramp from ~0.5 to ~1.0 over the sequence, accumulating context
- Others stay moderate (0.3-0.6), selectively gating new information
- Different units clearly specialize in different roles
Output Gate Modulation
The most diverse gate:
- Some units increase output gating toward the end of the sequence, preparing to expose stored information for the final classification
- Others oscillate, contributing different features at different time steps
The Cell State as Memory
Constant Error Carousel
The forget gate data confirms Hochreiter and Schmidhuber's hypothesis directly. With $f_t$ in the 0.8-1.0 range, the update
preserves most of the previous cell state while selectively adding new information. Even with $f_t \approx 0.9$, after 30 steps the retained fraction is $0.9^{30} \approx 0.04$ -- small, but enough to maintain a gradient pathway. In a vanilla RNN, the equivalent multiplicative decay drives this to effectively zero.
Overfitting Analysis
100% training accuracy by epoch 50, but test accuracy plateaus around 95% and slowly degrades. The widening loss gap (train: 0.0003, test: 0.3073 at epoch 100) is textbook overfitting on a small dataset. Fixes for production:
- Early stopping at epoch ~17 (peak test accuracy)
- Higher dropout (currently 0.3)
- More training data
Gate Coordination: The Copy Strategy
The gates learn a clean three-phase pattern for this task:
- Input gate opens at the first time step to write the relevant features into the cell state
- Forget gate stays near 1.0 to hold that information unchanged across 30 steps
- Output gate opens at the last time step to reveal stored memory for classification
This is the strategy you would design by hand -- but the network finds it through gradient descent alone.
LSTMs vs GRUs vs Transformers
GRU Simplification
GRUs (Cho et al., 2014) collapse the LSTM's two states into one and merge the forget/input gates into a single update gate. Fewer parameters, often similar performance on shorter sequences.
Transformer Comparison
- LSTM: Sequential processing, fixed-size memory, $O(1)$ per-step inference
- Transformer: Parallel processing, full context attention, $O(n)$ per-step inference
LSTMs still make sense for streaming and real-time applications where constant per-step cost matters.
Conclusion
A from-scratch 2-layer LSTM with 204,290 parameters reaches 95.7% peak test accuracy on a 30-step dependency task, hitting 90%+ within 5 epochs. The gate visualizations line up with theory: forget gates hold open to create gradient highways, input gates selectively write relevant information, and output gates control what gets read out for classification. Full code, training logs, and visualizations are on the GitHub repo.