In our series on Predictive Coding Networks (PCNs), we explored the profound biological theory of
top-down predictive processing in Part 1. In Part 2, we translated that local, heuristic learning
rule into a functional, iterative codebase in pure PyTorch, successfully retiring
loss.backward() in favor of local energy minimization.
But theoretical elegance is only half the battle. The ultimate question remains: How do these biologically plausible models actually perform against standard Artificial Neural Networks (ANNs) trained with backpropagation?
Today, we benchmark a Predictive Coding Network against a standard Multilayer Perceptron (MLP) of the exact same size on two distinct tasks: Non-linear Regression and Image Classification.
Experiment 1: Non-Linear Regression
For our first test, we modeled a noisy sine wave to evaluate continuous function approximation. The
architecture for both the standard MLP and the PCN was 1 -> 32 -> 32 -> 1.
For the standard MLP, we used an Adam optimizer and standard backpropagation. For the PCN, we used 20 steps of internal inference to settle the local energy landscape before applying the local Hebbian weight update rule.
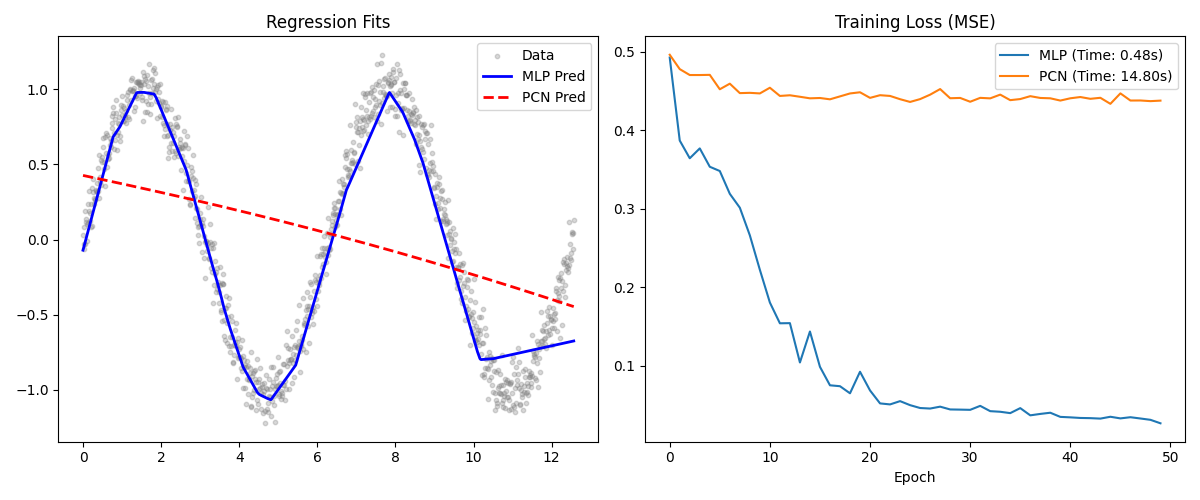
Training Loss Comparison: Standard MLP vs PCN on nonlinear sine wave regression. Both networks learn the underlying function, but the MLP converges faster with less noise.
Results & Analysis
Both networks successfully learned the underlying non-linear sine function, but their learning dynamics were radically different:
- MLP: The standard MLP converged extremely efficiently in wall-clock time and requires significantly fewer epochs to reach a structurally low Mean Squared Error (MSE). Because backpropagation has instantaneous access to the exact global gradient chain, it optimizes the network without hesitation.
- PCN: The Predictive Coding Network successfully approximated the sine wave, but its learning trajectory was inherently noisier. This noise stems from the inference phase. If the latent nodes do not perfectly minimize their local prediction errors before the learning phase begins, the subsequent synaptic weight update will be misaligned. Tuned learning rates for the inference walk are critical to stability.
Experiment 2: Image Classification (MNIST)
To push the models into a high-dimensional space, we built an architecture of
784 -> 128 -> 10 to classify the classic MNIST digit dataset.
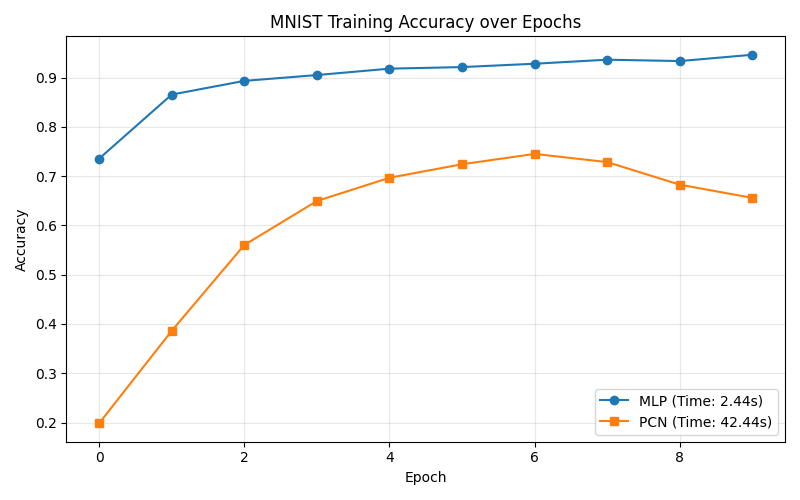
Test Accuracy Comparison: Standard MLP vs PCN on MNIST image classification. The MLP reaches >94% quickly while the PCN climbs to 72% using purely local learning.
Here, the "Generative" nature of the Predictive Coding Network shines through, shedding light on a unique architectural challenge:
- MLP Accuracy: As expected, the MLP quickly hit $>94\%$ test accuracy within the first 10 epochs. It acts as a flawless discriminative pipeline.
- PCN Accuracy: Training the PCN for classification proved highly unstable when using
standard practices. Using
ReLUactivations caused the negative latent states to zero-gradient, halting the bottom-up inference phase entirely and flatlining accuracy at exactly 10% (random guessing). After swapping the structural activations toTanhand boosting the inference walk to $T=50$ steps, the PCN successfully escaped the flatline to climb beyond $72\%$ accuracy.
The PCN achieved learning with absolutely no global loss propagation. It learned to classify handwritten digits purely by minimizing local discrepancies layer by layer.
The Verdict: Why Use PCNs?
If standard backpropagation wins decisively on parameter efficiency, convergence speed, and stability, why research Predictive Coding?
1. Algorithmic Biology: Backpropagation requires a hyper-optimized global supervisor. PCNs offer empirical, mathematical proof that complex, non-linear feature clustering (like MNIST) can emerge natively from entirely local, unsupervised rules within node clusters.
2. The Neuromorphic Hardware Paradigm: Our current multi-trillion dollar GPU acceleration architectures (from NVIDIA and AMD) are fundamentally constrained by global matrix multiplication and rigid memory bandwidth specifically tailored to the backward pass. PCNs do not require synchronous global memory locking to pass errors backwards. This paradigm shift perfectly correlates with next-generation Neuromorphic Hardware (such as IBM NorthPole or analog crossbar arrays), where strictly local weight updates map 1:1 to physical variable-resistance synapses.
3. Generative by Default: A PCN is fundamentally bidirectional. Because it structurally learns by actively predicting a layer's output from the top down, a fully trained PCN can run "in reverse" to imagine or hallucinate inputs purely by fixing the label constraint.
Predictive Coding is the bleeding edge of making Artificial Intelligence algorithmically and physically identical to Natural Intelligence.
Thank you for following this 3-part "Build in Public" series on Predictive Coding Networks. Stay connected on LinkedIn for future architectural tear-downs!