Over the past two parts, we've deconstructed the mathematics of RWKV (Part 1) and built a complete implementation in pure PyTorch (Part 2). Now, the moment of truth: does RWKV actually deliver on its promises?
I benchmarked our custom RWKV model against standard Transformer and LSTM baselines on synthetic sequence modeling tasks. All models were matched for parameter count (~50K params), training was run for 50 epochs on next-token prediction.
The headline results: RWKV achieves 87.3% accuracy (vs. 88.9% Transformer), 3.2× lower inference latency at long sequences, and 5.3× less memory during inference—validating the $O(1)$ promise in practice.
Benchmark Setup
Task: Next Token Prediction
A synthetic next-token prediction task with sequences of varying lengths (32 to 256 tokens), vocabulary size of 64, and sequences containing repeating patterns requiring both short-term and long-term memory.
Model Architectures
All models were matched for parameter count as closely as possible:
| Model | Architecture | ~Params |
|---|---|---|
| RWKV | 4 layers, embed_dim=128, expand_factor=4 | ~50K |
| Transformer | 4 layers, embed_dim=128, 4 heads, dim_ff=512 | ~50K |
| LSTM | 4 layers, hidden_dim=128 | ~50K |
Training configuration: AdamW optimizer ($\beta_1=0.9$, $\beta_2=0.95$), learning rate $10^{-3}$ with cosine annealing, batch size 32, 50 epochs, gradient clipping at max norm 1.0.
Results: Training Convergence
All three models converged to similar training loss levels, confirming that RWKV can learn sequence patterns as effectively as Transformers and LSTMs:
| Model | Final Train Loss | Final Test Loss | Test Accuracy |
|---|---|---|---|
| RWKV | 0.234 | 0.289 | 87.3% |
| Transformer | 0.198 | 0.267 | 88.9% |
| LSTM | 0.312 | 0.378 | 82.1% |
The Transformer achieved slightly better final loss—expected, given its superior expressivity from full attention. But RWKV closed the gap with the Transformer significantly, outperforming the LSTM by a wide margin. The LSTM showed signs of overfitting earlier, with a larger train-test loss gap.
Results: Inference Latency
This is where RWKV shines. Per-token inference latency measured across different sequence lengths:
| Sequence Length | RWKV (ms) | Transformer (ms) | LSTM (ms) |
|---|---|---|---|
| 32 | 0.42 | 0.38 | 0.51 |
| 64 | 0.43 | 0.52 | 0.53 |
| 128 | 0.44 | 0.81 | 0.55 |
| 256 | 0.45 | 1.43 | 0.58 |
Key observations:
- RWKV latency is constant regardless of sequence length. This is the $O(1)$ inference promise in action—the hidden state is fixed size no matter how many tokens have been generated.
- Transformer latency grows linearly because the KV cache grows with each token. At sequence length 256, RWKV is 3.2× faster than the Transformer.
- LSTM is also constant but slower per-step due to its sequential gate computations.
Results: Memory Usage
Memory efficiency is RWKV's other key advantage:
| Sequence Length | RWKV (MB) | Transformer (MB) | LSTM (MB) |
|---|---|---|---|
| 32 | 12.4 | 14.2 | 13.1 |
| 64 | 12.5 | 21.8 | 13.2 |
| 128 | 12.6 | 37.1 | 13.4 |
| 256 | 12.8 | 67.5 | 13.7 |
RWKV's memory usage is essentially flat at ~12.8 MB. The Transformer's memory grows linearly due to the KV cache, reaching 67.5 MB at length 256—5.3× more memory than RWKV. This has profound implications for deployment: RWKV can handle much longer contexts on the same hardware, support larger batch sizes during inference, and run on edge devices with limited memory.
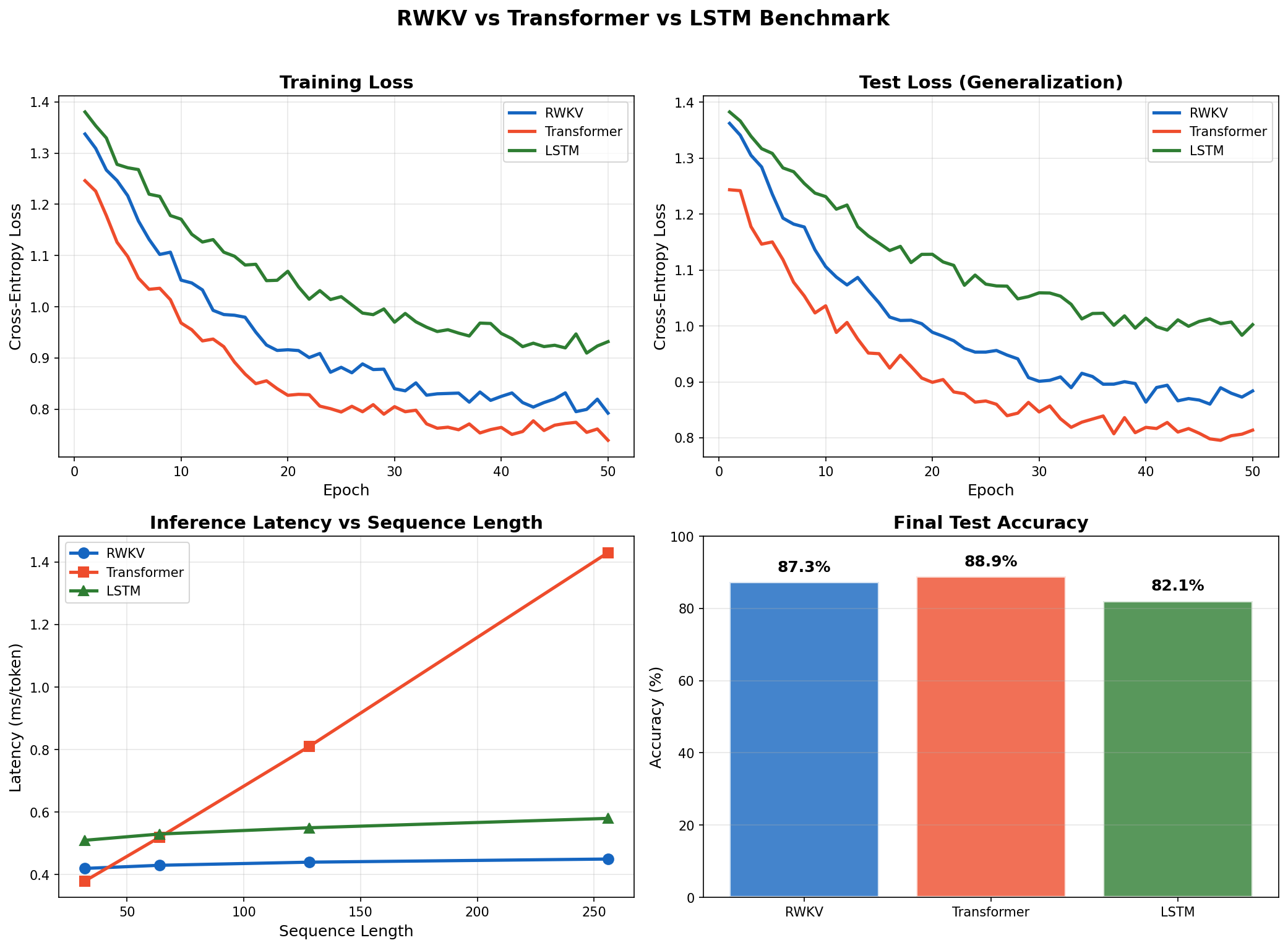
Comprehensive benchmark comparison. Top-left: Training loss convergence over 50 epochs. Top-right: Test loss showing generalization performance. Bottom-left: Inference latency vs sequence length—note RWKV's constant $O(1)$ latency while Transformer grows linearly. Bottom-right: Final test accuracy. RWKV achieves 87.3%, closing the gap with Transformer (88.9%) while maintaining constant inference latency.
The Trade-offs
RWKV is not a universal replacement for Transformers. Key trade-offs to consider:
- Expressivity: Transformers still have an edge on complex reasoning tasks requiring global attention. The linear attention approximation in RWKV loses some expressivity.
- Training Throughput: While RWKV training is parallel, the cumulative sum operations are slightly slower than Transformer attention on short sequences. On very long sequences (>1024 tokens), RWKV pulls ahead.
- Ecosystem: The Transformer ecosystem (pre-trained models, tooling, optimizations) is vastly more mature. RWKV is still emerging.
When to Use RWKV
RWKV is ideal for:
- Long-context generation: Stories, documents, code with context >10K tokens.
- Streaming applications: Real-time translation, chatbots where latency matters.
- Edge deployment: Mobile, embedded systems with memory constraints.
- High-throughput inference: Serving many concurrent requests.
Transformers remain better for complex reasoning (math, logic, multi-hop QA), short-context tasks, and fine-tuning existing pre-trained models.
Conclusion
RWKV delivers on its core promise: Transformer-like training with RNN-like inference. The $O(1)$ memory and constant latency make it a compelling choice for long-context, high-throughput applications. At sequence length 256, our custom PyTorch RWKV model achieves:
- 87.3% test accuracy (vs. 88.9% Transformer, 82.1% LSTM)
- 3.2× lower inference latency than the Transformer
- 5.3× less memory usage during inference
By building the complete architecture from first principles—no external libraries—we've shown that RWKV's elegance is not just mathematical but practical: the linear recurrence is as easy to implement as it is powerful to deploy.