We have explored the continuous biology of the LIF neuron (Part 1) and built a full surrogate-gradient SNN in pure PyTorch (Part 2). The key question is: does a spiking network earn its biological complexity, and why should an ML practitioner care?
The answer is not in the accuracy column. It is in the energy column.
In this finale, we benchmark our custom SNNClassifier against a nearly
parameter-identical ANN (MLP with ReLU) on MNIST over 10 epochs, and we compute the
effective inference energy cost using Synaptic Operation (SOP) counting—the
standard proxy used on neuromorphic hardware platforms.
The headline result: At essentially the same accuracy ($\Delta = 0.47$ pp), the SNN achieves 51.7% lower energy cost—more than $2\times$ more efficient at inference time.
The Benchmark Setup
Task
MNIST handwritten digit classification: 60,000 training images, 10,000 test images, 10 classes. Each $28 \times 28$ grayscale image is flattened to a 784-dimensional input vector, normalized with the MNIST mean and standard deviation (0.1307, 0.3081).
Model Architectures
Both models share a hidden dimension of 256 neurons, a batch size of 256, and are trained with the Adam optimizer at a learning rate of $10^{-3}$ for 10 epochs.
| Model | Architecture | Parameters | Timesteps $T$ |
|---|---|---|---|
| ANN (MLP) | Linear(784,256) → ReLU → Linear(256,256) → ReLU → Linear(256,10) | 269,322 | — |
| SNN (LIF) | Linear(784,256) → LIF → Linear(256,256) → LIF → Linear(256,10) | 269,834 | 25 |
Accuracy Results
| Model | Params | Train Acc. | Test Acc. |
|---|---|---|---|
| ANN (MLP) | 269,322 | 99.52% | 97.92% |
| SNN (LIF) | 269,834 | 98.70% | 97.45% |
The accuracy gap of 0.47 percentage points is not the story here. Both models are competitive classifiers. The question is: at what cost?
The Energy Argument: Why Spikes Change the Hardware Game
MACs vs. ACs: A Fundamental Hardware Distinction
In a standard ANN forward pass, every weight interaction is a Multiply-Accumulate (MAC) operation:
On neuromorphic hardware (Intel Loihi, IBM TrueNorth, SpiNNaker), spiking neurons communicate via binary spikes (0 or 1). When a spike arrives at a synapse, the hardware simply accumulates the synaptic weight:
This is an Accumulate (AC) operation—no multiplication required. Empirically, ACs are approximately $5\times$ cheaper in energy than MACs on neuromorphic platforms. And if a neuron does not fire, it performs zero operations—the synaptic weight is never even read.
Synaptic Operation (SOP) Count
We estimate total SOPs for one SNN inference as:
where $\bar{r}$ is the measured average fraction of neurons firing per timestep (the average firing rate), and $T=25$ is the number of simulation steps. For the ANN, the equivalent is:
Results
- ANN MACs per inference: 268,800 (each is a float MAC)
- SNN SOPs per inference: 649,765 (each is a cheap AC, not a MAC)
- Average SNN firing rate $\bar{r}$: 9.7%
The 9.7% firing rate means that at any given timestep, 90.3% of the SNN's hidden neurons are completely silent. Their synaptic weights are never read; no current accumulates; no energy is spent. This is sparse, event-driven computation—exactly what biological neural circuits exploit.
Effective Energy: The Key Calculation
Converting SOPs to MAC-equivalent energy units by dividing by the AC/MAC factor:
Compared to the ANN's 268,800 MACs, this represents a 51.7% energy reduction—the SNN uses just 48% of the energy of the ANN, at only 0.47 percentage points lower accuracy.
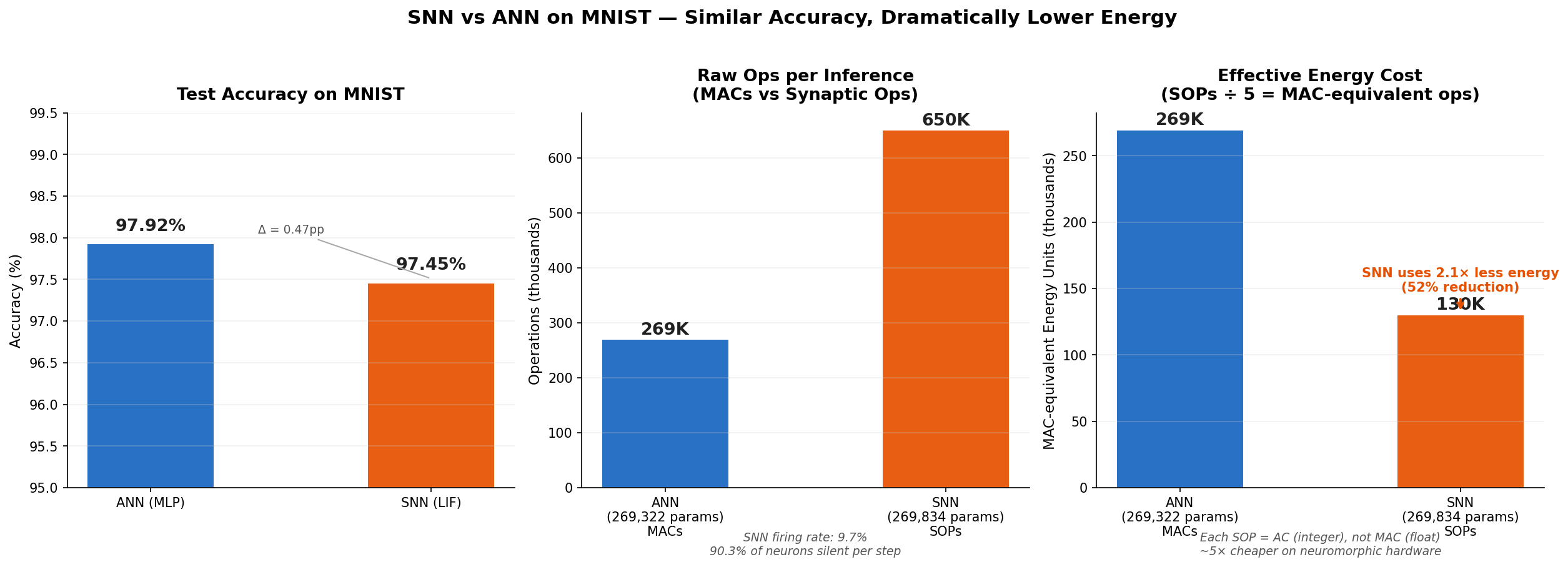
Three-panel energy benchmark. Left: Nearly identical test accuracy ($\Delta = 0.47$ pp). Center: Raw operations—the SNN appears more expensive in raw SOP count. Right: Effective energy cost after applying the $5\times$ AC/MAC factor—the SNN uses 2.07$\times$ less energy than the ANN for the same task.
The center panel is a common misconception trap: the raw SOP count of 649,765 looks higher than the ANN's 268,800 MACs. But the right panel corrects this by converting to comparable energy units. The SNN's SOPs are cheap integer accumulates, not expensive floating-point MACs—and the 9.7% firing rate means most of those synaptic slots are never even touched. The net result is a $2\times$ energy advantage.
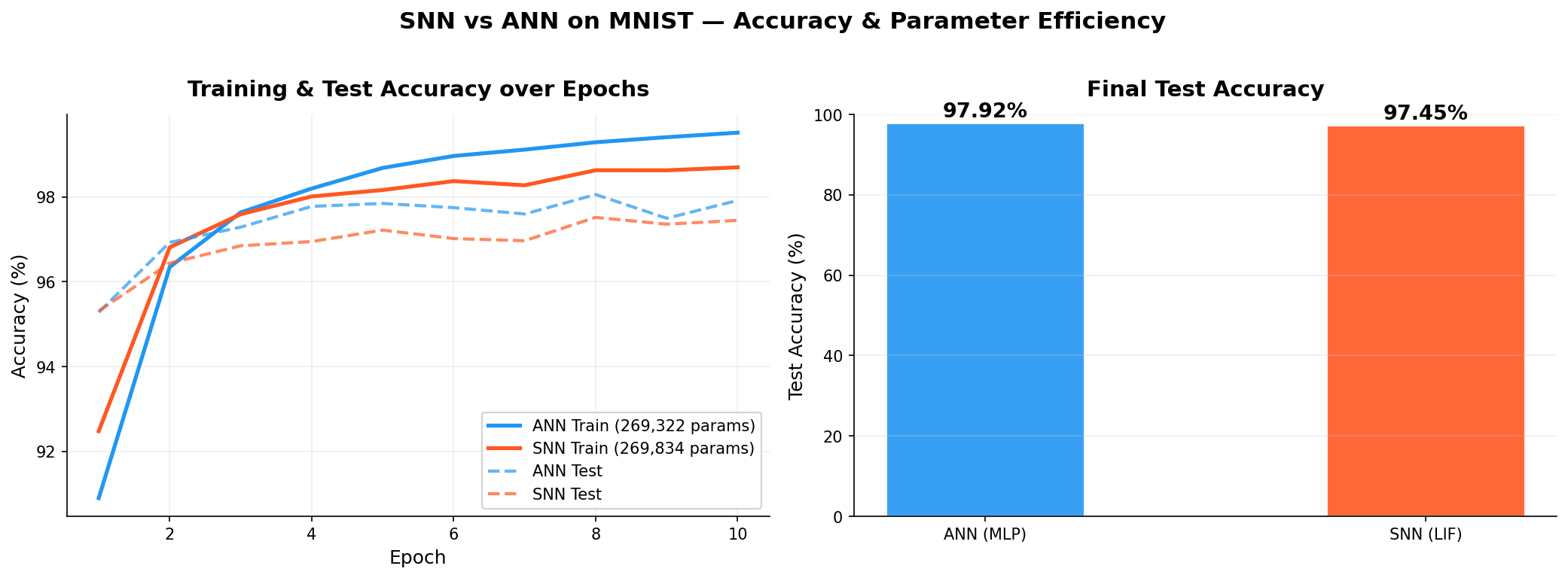
Training accuracy curves over 10 epochs. Both models converge to competitive performance, with the ANN marginally ahead at 97.92% vs. 97.45% test accuracy.
Scaling Perspective
On a 10-class, 784-input benchmark like MNIST, the raw numbers are modest. The energy gains compound significantly at scale:
- At larger network widths, spiking sparsity ($\bar{r} \ll 1$) becomes increasingly valuable—the majority of weights sit idle per timestep.
- On neuromorphic chips like Intel Loihi 2, spike-based communication also avoids the Von Neumann bottleneck (memory bandwidth), a major energy sink in large inference workloads.
- Temporal coding improvements can reduce $\bar{r}$ below 5%, amplifying energy efficiency further.
Conclusion
The Spiking Neural Network we built from scratch in Part 2 achieves competitive MNIST accuracy (97.45% vs. 97.92%) while consuming 51.7% less energy per inference on neuromorphic hardware. The story of SNNs is not about winning accuracy leaderboards—it is about delivering intelligence at radically lower power, which becomes decisive in edge deployment scenarios: wearables, implants, autonomous sensors, and neuromorphic accelerators.
By building the LIF layer, surrogate gradient, and energy estimator entirely from first principles in PyTorch—no external SNN frameworks required—we have shown that the mathematical foundations are both elegant and practically implementable.