Part 1 covered the LIF neuron. Part 2 built it in PyTorch. Now the question: does a spiking network actually earn its complexity?
Not in accuracy. In energy.
We benchmark our SNNClassifier (269,834 params) against a parameter-matched ANN
(269,322 params, MLP with ReLU) on MNIST for 10 epochs, then compute effective inference
energy via Synaptic Operation (SOP) counting--the standard proxy on neuromorphic
hardware.
Result: the SNN reaches 97.45% test accuracy (vs. 97.92% for the ANN, $\Delta = 0.47$ pp) at 51.7% lower energy cost.
Benchmark Setup
Task
MNIST digit classification. 60k training / 10k test images, 10 classes. Each $28 \times 28$ image is flattened to 784 dimensions and normalized (mean 0.1307, std 0.3081).
Model Architectures
Hidden dimension 256, batch size 256, Adam at $10^{-3}$, 10 epochs.
| Model | Architecture | Parameters | Timesteps $T$ |
|---|---|---|---|
| ANN (MLP) | Linear(784,256) → ReLU → Linear(256,256) → ReLU → Linear(256,10) | 269,322 | — |
| SNN (LIF) | Linear(784,256) → LIF → Linear(256,256) → LIF → Linear(256,10) | 269,834 | 25 |
Accuracy
| Model | Params | Train Acc. | Test Acc. |
|---|---|---|---|
| ANN (MLP) | 269,322 | 99.52% | 97.92% |
| SNN (LIF) | 269,834 | 98.70% | 97.45% |
A 0.47 pp gap. Both are competitive classifiers. The real comparison is cost.
Energy: MACs vs. ACs
The Hardware Distinction
In an ANN forward pass, every weight interaction is a Multiply-Accumulate (MAC):
On neuromorphic hardware (Intel Loihi, IBM TrueNorth, SpiNNaker), spikes are binary. A received spike triggers a weight Accumulate (AC)--no multiply:
ACs are roughly $5\times$ cheaper than MACs. And if a neuron does not fire, nothing happens--no weight read, no energy spent.
SOP Counting
Total SOPs for one SNN inference:
$\bar{r}$ is the measured average firing rate, $T=25$ simulation steps. For the ANN:
Measured Numbers
- ANN MACs per inference: 268,800
- SNN SOPs per inference: 649,765
- Average firing rate $\bar{r}$: 9.67%
At any given timestep, 90.3% of the SNN's hidden neurons are silent. Their weights are never read.
Effective Energy
Converting SOPs to MAC-equivalent units (dividing by the $5\times$ AC/MAC factor):
Against the ANN's 268,800 MACs: a 51.7% energy reduction. The SNN uses 48% of the ANN's energy at 0.47 pp lower accuracy.
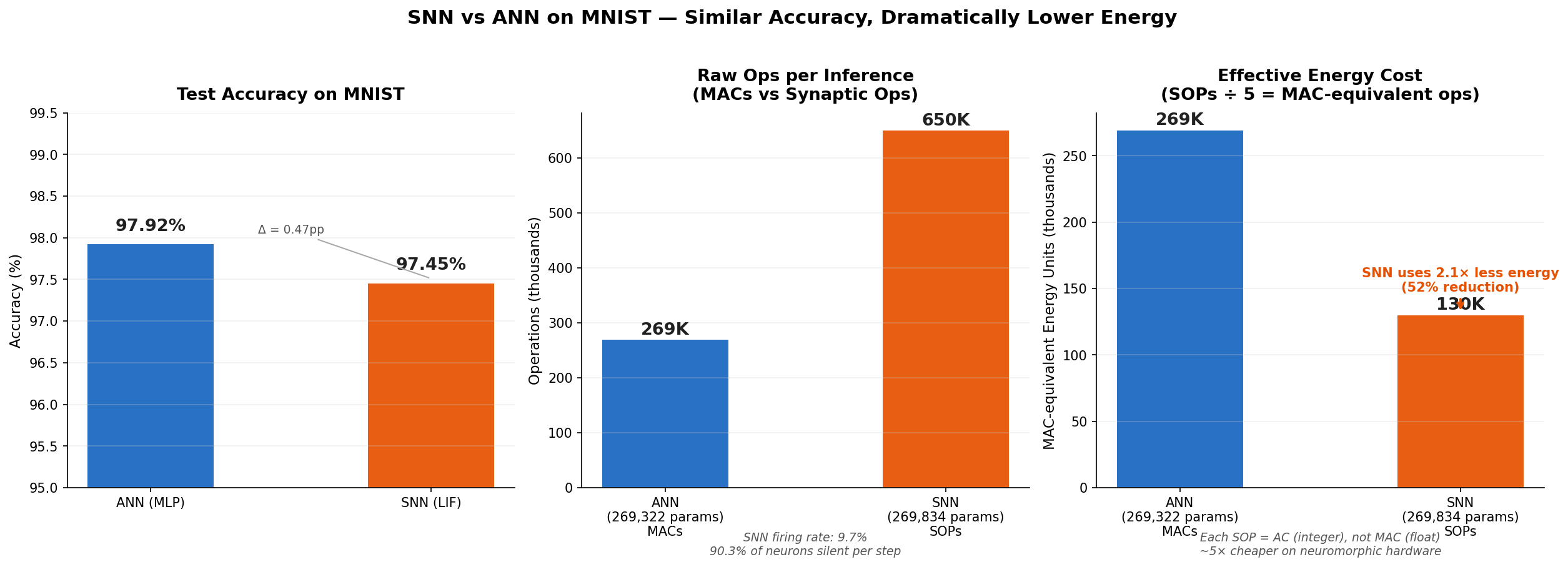
Left: test accuracy ($\Delta = 0.47$ pp). Center: raw operation counts (SOPs vs. MACs). Right: effective energy after the $5\times$ AC/MAC conversion--SNN uses $2.07\times$ less.
The center panel is deceptive: 649,765 SOPs looks worse than 268,800 MACs. But SOPs are integer accumulates, not float multiplies. After conversion, the SNN wins by $2\times$.
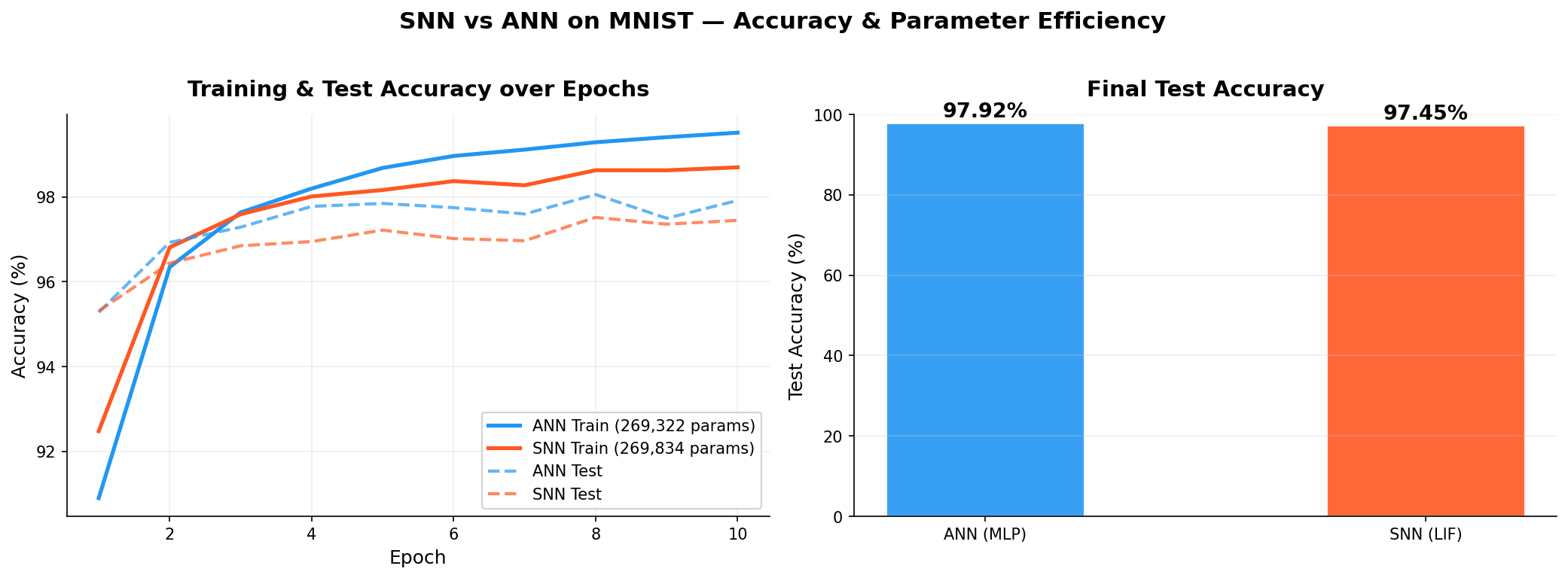
Training curves over 10 epochs. ANN: 97.92% test. SNN: 97.45% test.
Scaling Perspective
MNIST is a small benchmark. The energy advantage compounds at scale:
- Wider networks: sparsity ($\bar{r} \ll 1$) means most weights sit idle per timestep. The wider the layer, the more you save.
- Neuromorphic chips (Intel Loihi 2, etc.) also bypass the Von Neumann bottleneck on memory bandwidth, a major energy cost in large inference workloads.
- Temporal coding can push $\bar{r}$ below 5%, further amplifying the gap.
Conclusion
Our from-scratch SNN hits 97.45% on MNIST (vs. 97.92% for the ANN) while burning 51.7% less energy per inference on neuromorphic hardware. SNNs do not win accuracy contests. They win on power--which matters in edge deployment: wearables, implants, autonomous sensors, neuromorphic accelerators.