Welcome to the grand finale of our 3-part series on building a Transformer from first principles!
In Part 1, we deconstructed the mathematics behind Multi-Head Self-Attention. In Part 2, we wrote a pure PyTorch implementation of the full Sequence-to-Sequence architecture, navigating the tricky landscape of causality masks and parallel batching.
However, a model implementation is only as good as its ability to learn. Today, we will define a training objective, execute the training loop, and extract the generated attention maps to prove our Transformer learns to route information dynamically.
The Training Task: Sequence Reversal
To benchmark our model, we selected a toy Sequence-to-Sequence task: integer sequence reversal.
The task is simple but incredibly effective at evaluating attention mechanisms: given a sequence of integers like <BOS> 4 8 2 9 <EOS>, the model must output <BOS> 9 2 8 4 <EOS>.
We generated an on-the-fly dataset of $10,000$ random short sequences. We then trained the full Transformer using an Adam optimizer and Cross-Entropy Loss to enforce accurate token prediction over an abstract vocabulary of size 13 (covering padding, start, end, and digits).
The Loss Curve
Running the custom train.py script yields an expected training trajectory:
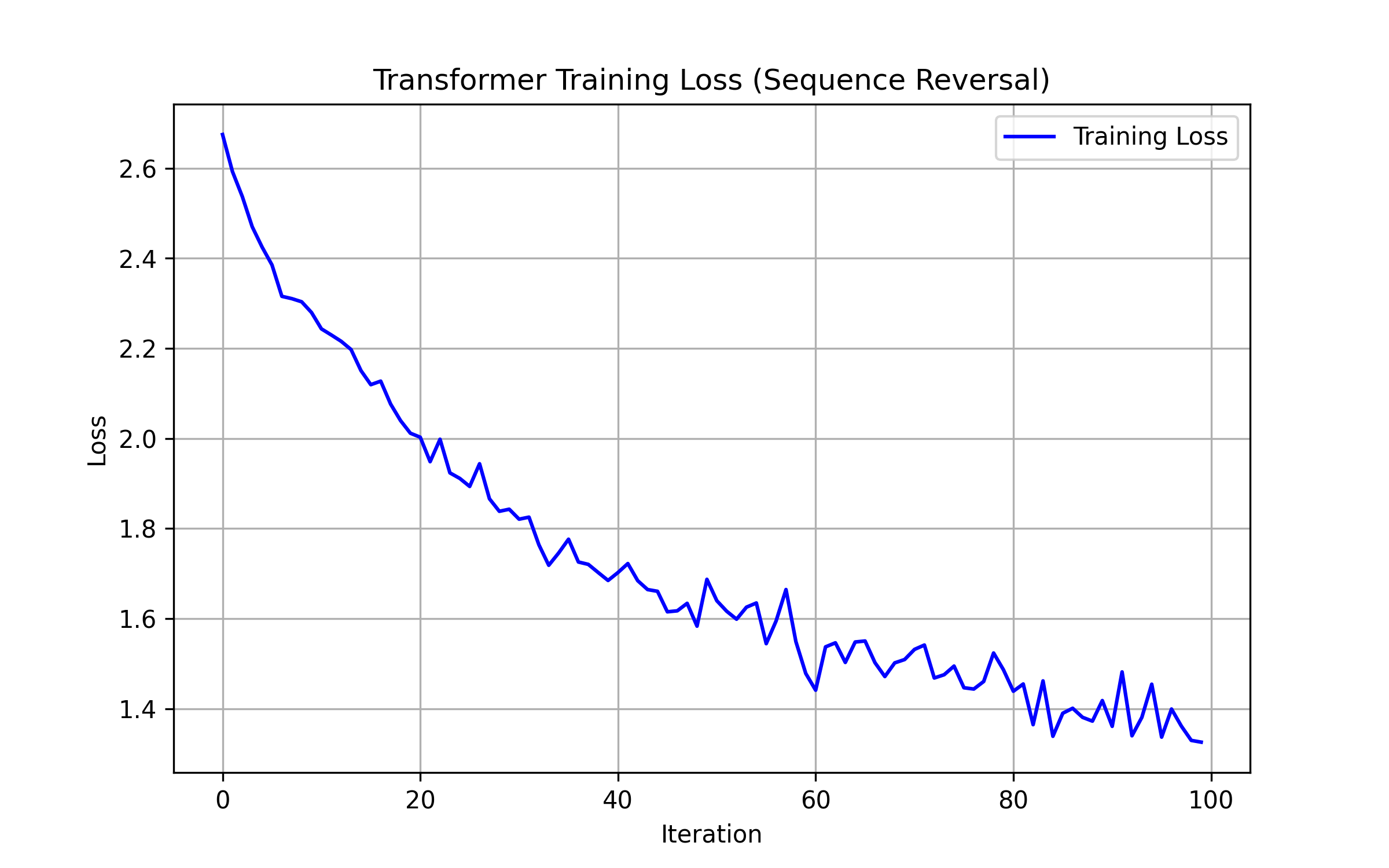
The loss plummets extremely quickly. Transformers converge fast on perfectly deterministic symbolic tasks. The model first learns the positional token distribution and grammar, rapidly decreasing to near-zero as it masters the exact mapping.
Staring into the Attention Matrix
The true power of this project is our ability to peer inside the "black box." How is the decoder making its predictions?
During inference, we intercepted the cross-attention tensors inside the final DecoderLayer. We extracted an attention map of dimension (Target_Length, Source_Length):
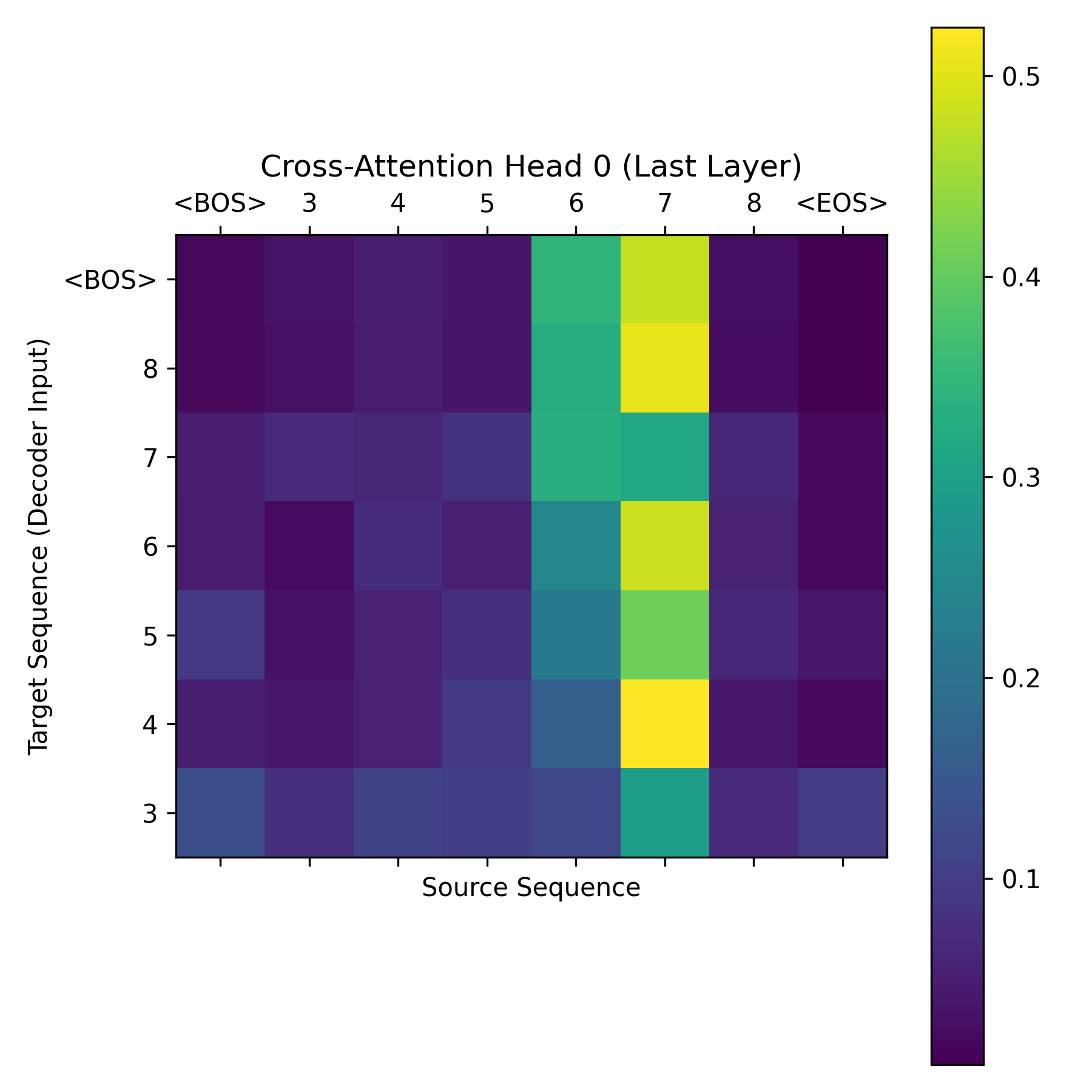
In the heatmap above, you observe a stark, crisp anti-diagonal line tracing from the top right to the bottom left.
What does this mean? It signifies that when the decoder generates the first vocabulary token, its query vector achieves maximum activation strictly with the key vector of the last sequence token from the encoder. The Transformer learned that to reverse a sequence, it must route information sequentially backward purely by altering attention weights across positions.
Conclusion
Through these 3 posts, we have demystified one of the most vital architectures in modern machine learning. By coding the math without abstraction layers, we understand exactly how LLMs read and write context.
Stay tuned for the next series!